Overview
In this article, I provide a brief history of the development of Reliability Centered Maintenance (RCM). And from there we explore 9 principles derived from RCM that will help you build an effective Preventive Maintenance Program. As a maintenance & reliability practitioner, you should know these RCM principles and live by them.

Fix it when it breaks
For most of human history, we’ve had a very simple approach to maintenance: we fixed
things as they broke. This served us well from our early days huddled around campfires
until about World War II. In those days industry was not very complex or highly mechanized. The downtime was not a major issue and preventing failures wasn’t a concern.
At the same time, most equipment in use was simple and more importantly, it was over-designed. This made equipment reliable and easy to repair. And most plants operated without any preventive maintenance in place. Maybe some cleaning, minor servicing, and lubrication, but that was about it.
This simple ‘fix it when it breaks’ approach to maintenance is often referred to as First Generation Maintenance

Things changed during World War II
Wartime increased the demand for many, diverse products. Yet at the same time,
the supply of industrial labour dropped. Productivity became a focus. And mechanization increased. By the 1950’s more and more complex machines were in use across almost
all industries. Industry as a whole had come to depend on machines.
And as this dependence grew, it became more important to reduce equipment downtime. ‘Fix it when it’s broken’ no longer suited industry.
A focus on preventing equipment failures emerged. And the idea took hold that failures
could be prevented with the right maintenance at the right time. In other words, the
industry moved from breakdown maintenance to time-based preventive maintenance.
Fixed interval overhauls or replacements to prevent failures became the norm.
This approach to preventive maintenance is known as Second Generation Maintenance.
More maintenance, more failures
Between the 1950s and 1970s, the third generation of maintenance was born in the aviation industry.
After World War II air travel became widely accessible and passenger numbers grew fast.
By 1958 the Federal Aviation Administration (FAA) had become concerned about reliability and passenger safety.
In the 1950’s and 1960’s the typical aircraft engine overhaul was every 8,000 hours. So
when the industry was faced with an increasing number of failures, the conclusion was
easy. Obviously component age must be less than the 8,000 hours that was being assumed. So, maintenance was done sooner. The time between overhauls reduced. Easy, right?
But increasing the amount of preventive maintenance had three very unexpected
outcomes. Outcomes that eventually turned the maintenance world upside down.
First of all, the occurrence of some failures decreased. That was exactly what everybody
expected to happen. All good.
The second outcome was that a larger number of failures occurred just as often as before.
That was not expected and slightly confusing.
The third outcome was that most failures occurred more frequently. In other words,
more maintenance leads to more failures. That was counter intuitive and a shock to
the system.


The birth of Reliability Centered Maintenance
To say that the results frustrated both the FAA and the airlines would be an understatement. The FAA worried that reliability had not improved. And the airlines worried about the ever-increasing maintenance burden.
So during the 1960’s the airlines and the FAA established a joint task force to find out what was going on. After analyzing 12 years of data the task force concluded that overhauls had little or no effect on overall reliability or safety.
For many years engineers had thought that all equipment had some form of wear out
pattern. In other words, that as equipment aged the likelihood of failure increased. But
the study found this universally accepted concept did not hold true.
Instead, the task force found six patterns describing the relationship between age and
failure. And that the majority of failures occur randomly rather than based on age.
The task force findings were used to develop a series of guidelines for airlines and airplane
manufacturers on the development of reliable maintenance schedules for airplanes.
The first guideline titled “Maintenance Evaluation and Program Development” came
out in 1968. The guide is often referred to MSG-1 and was specifically written for Boeing
747-100.
The maintenance schedule for the 747-100 was the first to apply Reliability Centered
Maintenance concepts using MSG-1. And it achieved a 25% to 35% reduction in maintenance costs compared to prior practices.
As a result, the airlines lobbied to remove all the 747-100 terminology from MSG-1. They
wanted the maintenance schedules for all new commercial planes designed using the
same process.
The result was MSG-2, released in 1970 titled “Airline/Manufacturer Maintenance Program Planning”.
Amazing results from the first applications of Reliability-Centered Maintenance (RCM)
The move to 3rd Generation or Reliability Centered Maintenance as outlined MSG-1
and MSG-2 was dramatic.
The DC-8’s maintenance schedule used traditional, 2nd Generation Maintenance concepts. It required the overhaul of 339 components and called for more than 4,000,000 labor hours before reaching 20,000 operating hours.
Compare that to the maintenance schedule for the Boeing 747-100, developed using
MSG-1. It required just 66,000 labor hours before reaching the same 20,000 operating
hours!
Another interesting comparison is to compare the number of items requiring fixed time
overhauls. The maintenance for the DC-10 was developed using MSG-2 and required the
overhaul of just 7 items versus the 339 on the DC-8.
And both the DC-10 and Boeing 747-100 were larger and more complex than the DC-8.
Impressive results. And the US Department of Defense (DoD) thought so, too.

The US Department of Defense gets involved in RCM
So in 1974, the DoD asked United Airlines to write a report on the processes used to
write reliable maintenance programs for civilian aircraft. And in 1978 Stan Nowlan and
Howard Heap published their report. It was titled “Reliability Centered Maintenance”.
Since then, a lot more work was done to progress the cause of Reliability-Centered
Maintenance. The airline industry has moved to MSG-3. John Moubray published his book RCM2 in the 1990’s introducing Reliability Centered Maintenance concepts to the industry at large.
Nowadays, RCM maintenance is defined through international standards. But it’s the
work done in the 60’s and 70’s that culminated in the Knowlan & Heap report in 1978 that all modern-day RCM maintenance approaches can be traced back to.
That’s now more than 40 years ago. So, any Maintenance & Reliability professional should
be familiar with it by now. It’s been around long enough. It’s well documented and widely available.
Unfortunately, we find that’s not the case. The principles of modern maintenance as developed in the journey to Reliability-Centered Maintenance are not always known or understood let alone applied.
The rest of this article will outline those principles. They should underpin any sound maintenance program.
One of the best summaries of these principles can be found in the NAVSEA RCM Handbook. I would highly recommend reading it. It is well written and easy to understand. And the following Principles of Modern Maintenance are very much built on the ‘Fundamentals of Maintenance Engineering’ as described in the NAVSEA manual.
9 Principles from RCM to create an effective PM program
Whether you are developing a new maintenance program. Or improving the maintenance program for an existing plant. All reliable maintenance programs should be based on the following Principles of Modern Maintenance:
Principle #1: Accept failures
Principle #2: Most failures are not age-related
Principle #3: Some failure consequences matter more than others
Principle #4: Parts might wear out, but your equipment breaks down
Principle #5: Hidden failures must be found
Principle #6: Identical equipment does not mean identical maintenance strategy
Principle #7: “You can’t maintain your way to reliability”
Principle #8: Good maintenance programs don’t waste your resources
Principle #9: Good maintenance programs become better maintenance programs
As a Maintenance & Reliability professional, you must understand these principles. You must practice and live by them.
Principle #1: Accept failures
Not all failures can be prevented by maintenance. Some failures are the result of events outside our control. Think lightning strikes or flooding. For events like these, more or better maintenance makes no difference. Instead, the consequences of events like these should be mitigated through design.
And maintenance can do little about failures that are the result of poor design, lousy
construction or bad procurement decisions.
In other cases, the impact of the failure is low, so you simply accept a failure (think general area lighting).
So, good maintenance programs do not try to prevent all failures. Good maintenance plans and programs accept some level of failures and are prepared to deal with the failures
they accept (and deem credible).
Principle #2: Most failure modes are not age-related
As explained above the RCM research by the airline industry has shown that 70% – 90% of failure modes are not age-related. Instead, for most failure modes the likelihood of
occurrence is random. Later research by the United States Navy and others found very
similar results.
This research is summarized in the six different failure patterns shown in the next page.
Apart from showing that most failure modes occur randomly. These failure patterns also
highlight that infant mortality is common. And that it typically persists. That means that the probability of failure only becomes constant after a significant amount of time in service.
Don’t interpret Curves D, E, and F to mean that (some) items never degrade or wear out.
Everything degrades with time, that’s life. But many items degrade so slowly that wear out
is not a practical concern. These items do not reach wear out zone in normal operating life.
So, what do these patterns tell us about our reliable maintenance programs?
Historically maintenance was done in the belief that the likelihood of failure increased
over time (first generation maintenance thinking). It was thought that well-timed maintenance could reduce the likelihood of failure. RCM has taught us that for at least
70% of equipment this simply is not the case.
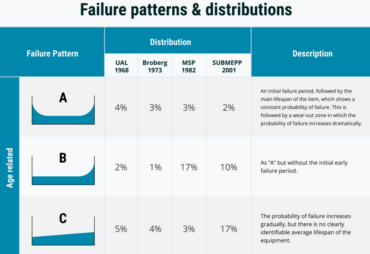
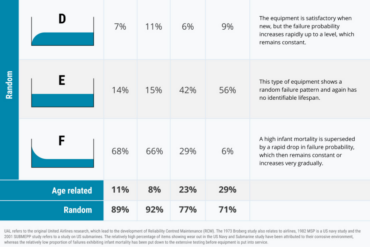
For the 70% of failure modes which has a constant probability of failure, there is no
point in doing time-based life-renewal tasks like servicing or replacement.
It makes no sense to spend maintenance resources to service or replace an item whose
reliability has not degraded. Or whose reliability cannot be improved by that maintenance task.
In practice, this means that 70% – 90% of equipment failure modes would benefit from
some form of condition monitoring. And only 10% – 30% can be effectively managed
by time-based replacement or overhaul. Yet most of our PM programs are full of time-based replacements and overhauls.
Strictly speaking, the studies that documented the fact that 70% to 90% of failure modes were random only found this in specific industries and applications. And they were
not conducted in major industries like oil & gas, mining, chemical manufacturing, food
processing, power generation etc. So, you could therefore dismiss these results with a
simple “well, we’re in a different industry, so obviously this doesn’t apply to us”. I strongly believe this principle applies to all heavy industry (more on that in a future article) and would strongly encourage you to approach this with the question “Why wouldn’t it apply to us?” and then carefully examine what you could gain from applying this principle.
Principle #3: Some failure consequences matter more than others
When deciding on whether to do a maintenance task consider the consequence of not
doing it. What would be the consequence of letting that specific failure mode occur?
Avoiding that consequence is the benefit of
your maintenance. The return on your investment.
And that is exactly how maintenance should be seen: as an investment. You incur a maintenance cost in return for a benefit in sustained safety and reliability. And as with all good investments, the benefit should outweigh the original investment.
So, understanding failure consequences is key to developing a good maintenance program. One with a good return on investment.
Just as not all failures have the same probability, not all failures have the same consequence. Even if it relates to the same type of equipment.
Consider a leaking tank. The consequence of a leaking tank is severe if the tank contains a
highly flammable liquid. But if the tank is full of potable water the consequence might not
be of great concern. Easy, right? But what if the water is required for firefighting?
The same tank, the same failure but now we might be more concerned. We would not
want to end up in a scenario of not being able to fight a fire because we had an empty tank due to a leak.
Apart from the consequence of a failure you also need to think about the likelihood of the
failure actually occurring.
Maintenance tasks should be developed for dominant failure modes only. Those failures
that occur frequently and those that have serious consequences but are less frequent
to rare. Avoid assigning maintenance to non-credible failure modes. And avoid analyzing non-credible failure modes. It eats up your scarce resources for no return.
A maintenance program should consider both the consequence and the likelihood
of failures. And since Risk = Likelihood x Consequence we can conclude that good
maintenance programs are risk-based.
Good maintenance programs use the concept of risk to assess where to use our scarce
resources to get the greatest benefit. The biggest return on our investment.
Principle #4: Parts might wear out, but your equipment breaks down
A ‘part’ is usually a simple component, something that has relatively few failure modes.
Some examples are the timing belt in a car, the roller bearing on a drive shaft, the cable
on a crane.
Simple items often provide early signals of potential failure, if you know where to look.
And so, we can often design a task to detect potential failure early on and take action prior
to failure.
For those simple items which do “wear out” there will be a strong increase in the probability of failure past a certain age. If we know the typical wear outage for a component, we can schedule a time-based task to replace it before failure.
When it comes to complex items made of many “simple” components, things are
different.
All those simple components have their own failure modes with its own failure pattern.
Because complex items have so many, varied failure modes, they typically do not exhibit
wear outage. Their failures do not tend to be a function of age but occur randomly. Their
probability of failure is generally constant as represented by curves E and F.
Most modern machinery consists of many components and should be treated as complex
items. That means no clear wear outage. And without clear wear out age performing time-based overhauls is ineffective. And wasteful of our scarce resources.
Only where we can prove that an item has wear outage does performing time-based
overhaul or component replacement make sense.
Principle #5: Hidden failures must be found
Hidden failures are failures that remain undetected during normal operation. They only
become evident when you need the item to work (failure on demand). Or when you conduct a test to reveal the failure – a failure finding task.
Hidden failures are often associated with equipment with protective functions.
Something like a high-high pressure trip. Protective functions like these are not normally active. They are only required to function by exception to protect your people from injury or death. To protect the environment from a major impact or protect our assets from major damage. This means we pretty much always conduct failure finding maintenance tasks on equipment with protective functions.
To be clear, a failure finding task does not prevent failure. Instead, a failure finding task
does exactly what its name implies. It seeks to find a failure. A failure that has already
happened, but has not been revealed to us. It has remained hidden.
We must find hidden failures and fix them before the equipment is required to operate.
Principle #6: Identical equipment does not mean identical maintenance strategy
Just because two pieces of equipment are the same doesn’t mean they need the same maintenance. In fact, they may need completely different maintenance tasks.
The classic example is two exactly the same pumps in a duty – standby setup.8 Same
manufacturer, same model. Both pumps process the exact same fluid under the same
operating conditions. But Pump A is the duty pump, and Pump B is the standby. Pump A
normally runs and Pump B is only used when Pump A fails.
When it comes to failure modes Pump B has an important hidden failure mode: it might
not start on demand. In other words, when Pump A fails or under maintenance, you
suddenly find that Pump B won’t start. Oops.
Pump B doesn’t normally run so you wouldn’t know it couldn’t start until you came to start it. That’s the classic definition of a hidden failure mode. And hidden failure modes like this require a failure finding task i.e. you go and
test to see if Pump B will start. But you don’t need to do this for Pump A because it’s always running (unless when it’s off or failed).
So when building a maintenance program you must consider the operating context (RCM
is very clear on this, but other approaches sometimes neglect operating content).
A difference in criticality can also lead to different maintenance needs. Safety or production critical equipment will need more monitoring and testing than the same equipment in low criticality service.
It’s important to reinforce that identical equipment may need different maintenance
requirements. This is far too often forgotten or simply ignored for convenience. But you
could find yourself facing critical failures by ignoring this basic concept. Especially if you
use a library of preventive maintenance tasks.
Principle #7: “You can’t maintain your way to reliability”
I love this quote from Terrence O’Hanlon and it’s so very true. Maintenance can only
preserve your equipment’s inherent design reliability and performance.
If the equipment’s inherent reliability or performance is poor, doing more maintenance will not help. No amount of maintenance can raise the inherent reliability of a design. To improve poor reliability or performance that’s due to poor design, you need to change
the design. Simple.
When you encounter failures – defects – that relate to design issues you need to eliminate
them.
Sure, the more proactive and more efficient approach is to ensure that the design is right,
to begin with. But all plants startup with design defects. Even proactive plants. And that’s why the most reliable plants in the world have an effective defect elimination program in place.
Principle #8: Good maintenance programs don’t waste your resources
This seems obvious, right? But when we review PM programs we often find maintenance tasks that add no value. Tasks that waste resources and actually reduce reliability and availability.
It’s so common for people to say “whilst we do this, let’s also check this. It only takes 5
minutes.” But 5 minutes here and there, every week or every month and we’ve suddenly wasted a lot of time. And potentially introduced a lot of defects that can impact equipment reliability down the line.
Another source of waste in our PM programs is trying to maintain a level of performance
and functionality that we don’t actually need.
Equipment is often designed to do more than what it is required to do in its actual operating conditions. As maintainers, we should be very careful about maintaining to design capabilities. Instead, in most cases, we should maintain our equipment to deliver to operating requirements. Maintenance done to ensure equipment capacity greater than actually needed is a waste of resources.
Similarly, avoid assigning multiple tasks to a single failure mode. It’s wasteful and it makes it hard to determine which task is actually effective. Stick to the rule of a single, effective task per failure mode as much as you can. Only for very high consequence failure modes should you consider having multiple, diverse tasks to a single failure mode.
Most organizations have more maintenance to do than resources to do it with. Use resources on unnecessary maintenance, and you risk not completing necessary maintenance. And not completing necessary maintenance, or completing it late, increases the risk of failures.
And when that unnecessary maintenance is intrusive it gets worse. Experience shows
that intrusive maintenance leads to increased failures because of human error. This could
be simple mistakes. Or because of defective materials or parts, or errors in technical documentation.
A lot of maintenance is done with the equipment off-line. So doing unnecessary maintenance can also increase production losses.
So make sure you remove unnecessary maintenance from your system. Make sure you
have a clear and legitimate reason for every task in your maintenance program. Make sure
you link all tasks to a dominant failure mode. And have clear priorities for all maintenance
tasks. That allows you to prioritize tasks. In the real world, we are all resource-constrained.
Principle #9: Good maintenance programs become better maintenance programs
The most effective maintenance programs are dynamic. They are changing and improving continuously. Always making better use of our scarce resources. Always becoming more effective at preventing those failures that matter to our business.
When improving your maintenance program
you need to understand that not all improvements have the same leverage:
First, focus on eliminating unnecessary maintenance tasks. This eliminates the direct
maintenance of labor and materials. But it also removes the effort required to plan,
schedule, manage, and report on this work.
Second, change time-based overhaul or replacement tasks into condition-based tasks.
Instead of replacing a component every so many hours, use a condition monitoring technique to assess how much life the component has left. And only replace the component when actually required.
And third, extend task intervals. Do this based on data analysis, operator and maintainer
experience. Or simply on good engineering judgment. Remember to observe the results. The shorter the current interval, the great�er the impact when extending that interval.
For example, adjusting a daily task to weekly reduces the required PM workload for that task by more than 80%. This is often the simplest and one of the most effective improvements you can make.
RCM FAQs
Before I wrap up this article, I wanted to answer some of the most common FAQs
relating to reliability centered maintenance, and these are:
What is reliability-centered maintenance?
Reliability-centered maintenance (RCM) is an internationally defined, structured decision-making process to develop or optimize a Preventive Maintenance Program. RCM focuses on preserving system functions rather than preserving equipment. The most fundamental requirement of any RCM process is that it must adequately and completely answer the following seven questions:
1. What are the functions and associated design performance standards for the
asset in its current operating context?
2. In what way can the asset fail to fulfill its functions?
3. What causes each possible functional failure?
4. What happens when each function of failure occurs?
5. In what way does each failure matter?
6. What should we do to predict or prevent each failure?
7. What should we do if a suitable proactive task cannot be found?
When done well, RCM will deliver highly effective and efficient PM programs, but implementing RCM requires significant expertise and resources. So, you need to use it wisely.
RCM is defined through a set of international standards: SAE JA1011 titled “Evaluation
Criteria for Reliability Centered Maintenance Processes” and SAE standard JA1012 titled “A Guide to The Reliability Centered Maintenance Standard”.
What is the difference between RCM and FMEA?
Failure Mode Effects Analysis (FMEA) is a step in the reliability centered maintenance (RCM) process, but RCM does a lot more than just analyzing functional failures. It focuses on defining functions, being clear on the operating context and selecting the right maintenance tasks based on the analysis of the different failure modes.
I like to say that RCM is function-based, Preventive Maintenance Optimization (PMO)
is task-based and FMEA is equipment based, but all good analyses are failure mode based!
What are the types of reliability-centered maintenance?
Be very careful with the idea that there are ‘types of reliability centered maintenance’.
People do talk about classical RCM and accelerated RCM. Classical RCM is the RCM process as originally defined by Nowland & Heap and now documented in SAE JA1011 and SAE JA1012. Accelerated RCM is an adaption of the classical RCM process, and there are quite a few variations – some are robust, but others are not. Buyer beware!
What is the overall goal of RCM?
The overall goal of reliability-centered maintenance is to achieve the required reliability levels for a system, at optimized maintenance and cost levels by focusing on the preservation of key functions.
References
I wrote this article based on a number of key sources listed below (and throughout the article). I strongly recommend getting yourself a copy of Moubray’s book on Reliability Centered Maintenance if don’t already own a copy. And I’d definitely get the NAVSEA Reliability Centered Maintenance (RCM) manual as it’s well-written and easy to understand:
• Moubray, J. (1997) Reliability Centered Maintenance Second Edition. Industrial Press.
• NAVSEA (2007) Reliability Centered Maintenance (RCM) Handbook [S9081-AB-GIB-010].
• Allen, T. M. (2001) ‘U.S. Navy Analysis of Submarine Maintenance Data and the Development of Age and Reliability Profiles’.
• White Paper (no date) ‘What is Reliability Centered Maintenance?’
• Wikipedia (2017) Reliability-centered maintenance.
• NASA (2008) Reliability-Centered Maintenance Guide.






